Why Working with Content is Hard for Developers
April 18, 2022
How we work with content on the web has shifted dramatically since the early days. Yet, working with content is still too difficult for developers.
- Traditional CMSs require a lot of knowledge and effort to build, deploy, and maintain.
- Static site generators don't scale well beyond hobby sites.
- As revolutionary as headless CMSs were, they didn't make building front-end applications easier.
- Gatsby re-imagined the experience of building a website, and yet the opinions it imposes on working with content are limiting.
- Modern frameworks have brought an incredible developer experience, but require that developers manually build a mechanism to process content.
These reasons are why we built Contentlayer.
Over the last two decades, we’ve seen a major shift from template-based content to treating content as data that we can feed into our component-based pages. This shift was made possible through a number of milestones.

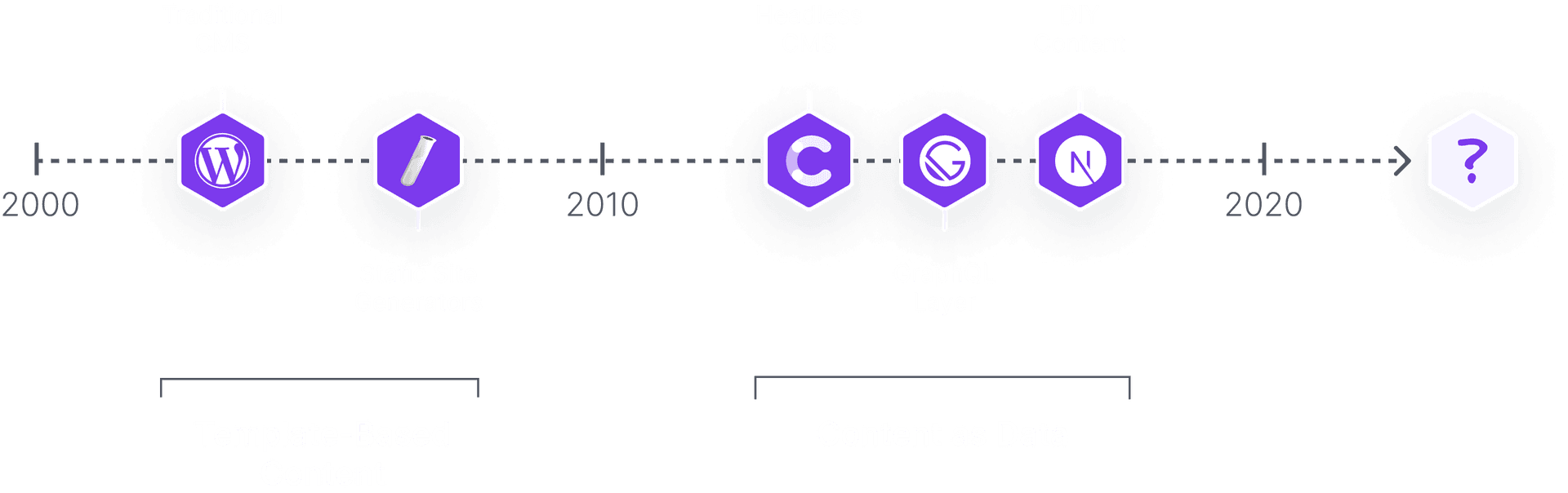
And yet, while each incremental adjustment has improved the developer experience when working with content, it is still a tiresome process to work with content within a web project.
Let’s look at each of these incremental improvements before suggesting the next step in this evolution.
Template-Based Content
In the early days of the web, content was tightly-coupled with code. The introduction of server-side templating and database-driven content brought us into a new era of handling content on the web.
1. Traditional CMS Separated Content from Code
Content Database
Monolithic Framework
Server-side Templates
Early web content management systems like Drupal (2001) and WordPress (2003) were game-changers for developers. Before them, content and code were combined. You couldn’t write content for the web without also writing HTML. That doesn’t sound fun, does it?
Traditional CMSs are also known as monolithic applications, which means that the entire application is tightly coupled. Content is edited through a CMS and stored in a database. When users visit the website, the front end retrieves the necessary content from the database, runs it through a server-side templating language, and delivers HTML to the user’s browser. All of this is accomplished with a single application, often on a single web server.
Monolithic Applications are Limiting
Although WordPress and Drupal are still around and highly popular today, we don’t talk about them much in conversations on developer experience.
- Managing infrastructure: Developing a monolithic application usually means managing the infrastructure of that application. You have to know how to work with web servers. You have to be well-versed not just in making database queries, but in managing and optimizing databases themselves.
- Slow and insecure: Though traditional CMSs often have caching mechanisms, they are notorious for slow performance and security vulnerabilities.
- Not sufficient for today's needs: The tools we have at our disposal today turn many developers away from what is becoming an antiquated pattern for building web experiences.
2. Static Site Generators Offered a Simplified Approach to Building Content-Driven Websites
Local Content
Static Site Generator
Server-side Templates
About five years after web-based CMSs were making a splash, Jekyll (2008) came onto the scene to serve the brand new GitHub (2008) and its Pages feature. Jekyll and GitHub Pages led a movement back to static sites as a result of the challenges in managing monolithic applications. There are now hundreds of SSG frameworks, and Jekyll remains among the most popular.
Jekyll was made possible by the rising trend of developers writing content in markdown. Markdown (2004) had been established a few years prior to Jekyll as a means to represent formatted text without the tedium of writing HTML.
Jekyll and many of the traditional SSGs worked by authoring content in local markdown files (or JSON, YAML, etc.), converting the frontmatter and body content to variables, and then running those variables through a server-side templating language like Liquid.
Storing content as plain text files in a Git repo was an early instance of what we now call Git CMS, which continues to be a developer-centric way to build websites. Git-based content made building and managing custom websites more trivial than ever for developers.
Developer Experience with SSGs Degrades Beyond the Hobby Site
The main problem with this pattern was that it couldn’t really extend much beyond the hobby project. The same remains true for SSGs like Hugo that came later. Though each framework in this category has its own set of features and limitations, these are the most common:
- Validations: Validating content is either not an option or must be done manually.
- TypeScript: Strongly-typing data is typically not an option. For JavaScript-based SSGs like 11ty, it’s possible, but challenging to implement.
- Relationships: Creating complex relationships among content is often a manual process, and can drastically lengthen build times.
- Components & Interactivity: Client-side component libraries are not supported out of the box. Interactivity is inherently more difficult to implement and manage.
- Performance: Though some SSGs are optimized for build performance (e.g. Hugo), many slow down significantly as the number of files grows.
- Tight Coupling: Content and code are tightly coupled, which means it’s difficult to have a source of truth for content serving multiple websites.
Content as Data
With the advent of more capable front-end frameworks like Angular and React replacing server-side templating languages like Liquid, a new approach for retrieving content was needed. Thus began the movement to treat content as data.
3. Headless CMS Decoupled Content and Code
Headless CMS
API Client
React Pages
Fast forward several more years and Contentful (2013) is launched, and begins to popularize the idea of a headless CMS. With a headless CMS, content is managed in a separate application and accessed via an API. This is also referred to as an API-Based CMS.
Think of this pattern as splitting a monolithic application in half, where you (the developer) don’t have to manage the content-editing portion. You worry more about accessing that content via an API.
Headless CMSs emerged during the API economy boom and at the height of the single-page application (SPA) popularity. Many websites would use an API client to access content from the CMS via an API, and feed that through client-side templates, made possible through early libraries like Angular and React.
The major benefits were:
- Simplified front ends: Developers no longer had to manage the content-editing mechanism for a website. No more databases or authentication for the typical websites.
- Multiple front ends (omnichannel): A single content source could serve multiple front-end sites.
- Unlocking SSGs for editors: Non-technical content editors could manage content for static sites without needing to access Git/GitHub.
Front Ends Weren’t Easier to Build Because of API-Driven Content
As groundbreaking as these benefits were, they didn’t actually make the process of building a website any easier.
- Added complexity: It added complexity in a lot of ways. If using a classic web framework like Ruby to manage the front end, you’d have to make API calls for data, rather than being able to use the standard and familiar ORM.
- Additional layer: With SSGs, the addition of a headless CMS meant adding another layer to the application. You’d often still have to cache that data to local files so the SSG could read and render it.
- Availability risk: Because content was stored in a separate application, the risk of content not being available increased.
- Previewing difficulties: Headless CMS also made it more difficult to preview content before publishing, especially when building the site using an SSG.
4. Gatsby Popularized Content as Data using GraphQL
Local/Remote Content
Gatsby GraphQL Layer
React Pages
A couple of years after Contentful hit the scene, Gatsby (2015) was born. Though a static site generator at its core, Gatsby brought with it two game-changing ideas that would eventually place it in a new category of tools we now call meta frameworks:
- React pages: Gatsby used React as its templating language, which meant that developers could build interactive, component-based sites without configuring and managing a complex JavaScript bundling process during the build.
- Content as data: Gatsby treated content as data. Using a GraphQL layer, developers could run queries and write server-side logic in JavaScript (Node.js), and then feed that data into page-level React components.
This was a completely new way of building websites. And the timing happened to coincide with the emergence of Netlify, which made deploying static sites near trivial.
Content Processing in Gatsby is too Opinionated
Although Gatsby suffered build time challenges similar to other early SSGs, the problem with Gatsby isn’t (exclusively) the build. The bigger problems were found in the opinionated GraphQL layer used to convert content to data. There’s a lot of magic going on under the hood that can lead to a degraded developer experience. For example:
- GraphQL required: To work with Gatsby, you already have to learn React. Adding this layer means yet another thing (GraphQL) developers have to know to use the tool.
- Content validations: Gatsby doesn’t provide content validations out of the box.
- Loose modeling structure: When working with local markdown, there is no concept of modeling. The content appears structured, but comes as large data objects with potentially conflicting properties and types. A lot of type- and presence-checking is often required.
- Lack of TypeScript: Seven years later and many versions later, it’s still difficult to work with TypeScript.
5. Modern Frameworks are Unopinionated on Content Processing
Local/Remote Content
DIY Content Processor
React Pages
Next.js (2016), another React meta framework, followed right on Gatsby’s heels and brought with it two additional new patterns:
- Variable rendering techniques: Within a single site, developers could choose whether a page should be statically rendered or server-side rendered. Suddenly we had the power of on-demand content without the need for a single-page application or client-side data fetching.
- DIY content processing: Next.js brought no opinion on how content should be handled. It left the GraphQL layer out and instead focused on providing developers the tools they needed to build powerful websites, while bringing content from anywhere.
Building a Content-Processing Mechanism is Really Difficult
Next.js was a massive improvement in developer experience over Gatsby. Yet, to get that boost in DX, we as developers had to build the content-processing mechanism for our site. We’re responsible for figuring out how to convert content into data and to feed that data to our page components.
To build this type of mechanism is a lot of work. And yet, not doing this work with high quality has the effect of degrading the developer experience, which is one of the primary drivers that leads developers to choose Next.
Putting the ideal content processing mechanism in place means accounting for:
- Low-level code: Writing the processing logic, including working with content-processing libraries and their plugins. This is a lot of base-level logic and adds a number of dependencies to your project.
- Caching: Caching processed data. Caching is hard. Not caching degrades the developer experience.
- Content relationships: Rich and complex content associations, so that objects can live as individual content files but be embedded as necessary when used as data.
- Live reloading: For some frameworks, like Next.js, pages are not live-reloaded automatically when editing markdown content. That’s another mechanism to build.
- TypeScript support: Generating/writing type definitions. If you want to work with TypeScript and strongly type the data, that must be generated manually.
- Validations: Data validation logic will have to be implemented manually, or you’ll want to build an abstracted system that accepts validation settings through configuration.
6. Contentlayer Makes Content Easy for Developers
Content
Contentlayer
Pages
This is why we created Contentlayer. Contentlayer makes working with content easy for developers.
For modern meta frameworks, Contentlayer is the glue between content and code. It is a content-processing mechanism that converts content into data that can be easily consumed by your pages and components.
Contentlayer provides the missing piece needed to maximize developer experience for modern frameworks by including the following features:
- Familiarity:
importcontent just as you would any other library or component - Validations: Built-in and configurable content validations
- Performance: Incremental and parallel builds
- TypeScript support: Strong-typed data (TypeScript types are generated automatically)
- Live reloading: When supported by the framework
Learn more about Contentlayer by reading the launch post or getting started
today!

Sean C Davis
@seancdavis29Related Posts


Introducing Contentlayer (Beta): Content Made Easy for Developers
April 21, 2022
Johannes Schickling
Working with content data (e.g. Markdown files or CMS) is a surprisingly difficult and laborious task when developing modern sites (e.g. with Next.js). Contentlayer is a content SDK that aims to make content easy for developers.
Read more